GStreamer CI Support for Embedded Devices
A look at introducing a Raspberry Pi to GStreamer's CI system
Omar Akkila's Personal /dev/null
GStreamer is a popular open-source pipeline-based multimedia framework that has been in development since 2001. That’s 17 years of constant development, triaging, bug fixes, feature additions, packaging, and testing. Adopting a Jenkins-based Continuous Integration (CI) setup in August 2013, GStreamer and its dependencies are now built multiple times a day with each commit. Prior to that, the multimedia project used a build bot hosted by Collabora and Fluendo. At the time of this writing, GStreamer is built for the Linux (Fedora & Debian), macOS, Windows, Android, and iOS platforms. A very popular deployment target for GStreamer are embedded devices, but they are not targeted in the current CI setup.This meant additional manpower, effort, and testing outside of the automated tests for every release of GStreamer to validate on embedded boards. To rectify this, a goal was devised to integrate embedded devices into the CI.
Now, this meant more than just emulating embedded targets and building GStreamer for them. The desire is to test on physical boards with as much as automation as possible. This is where the the Linaro Automated Validation Architecture (LAVA) steps into play. LAVA is a continuous integration automation system, similar to Jenkins, oriented towards testing on physical and virtual hardware. Tests can range anywhere between simple boot testing to system-level testing. The plan being that GStreamer CI will interface with LAVA to run the gst-validate test suite on devices.
Architecturally, LAVA operates through a master-worker relationship. The master is responsible for housing the web interface, database of devices, and scheduler. The worker is responsible for receiving messages from the master and dispatching all operations and procedures to the Devices Under Test (DUT). At Collabora, we host a LAVA instance with a master and maintain a lab of physical devices connected to a LAVA worker in our Cambridge office. For the preliminary iteration of embedded support, the aim is to introduce a Raspberry Pi to the GStreamer CI. Collabora’s infrastructure is used as a playground to test and research. The Raspberry Pi is both popular and it offers the complex use-case of creating special builds of GStreamer components due to its design. Conveniently, one of the devices integrated with our worker is a Raspberry Pi 2 Model B - hereafter referred to as ‘RPi’.
GStreamer CI already makes use of Jenkins’ pipeline capabilities for builds. A single master job downstreams multiple jobs such as validation and builds for different architectures. Our embedded projects can be broken down into different phases which can represent different stages in a pipeline. Visually, this looks like:
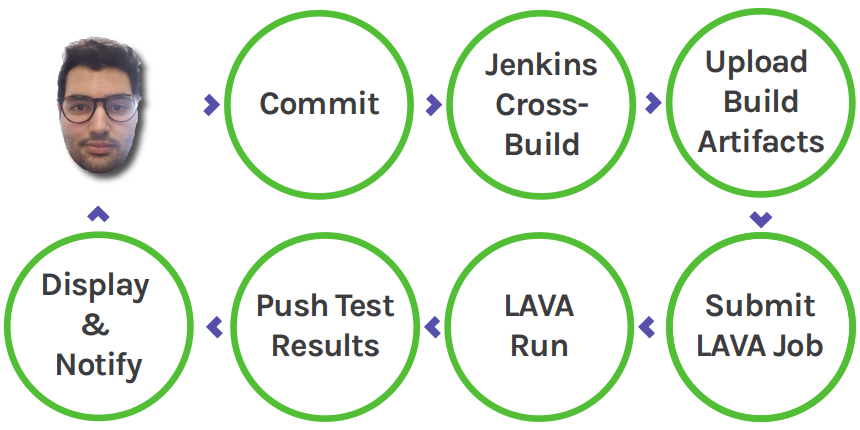
In terms of jobs we have:
-
Build GStreamer for the RPi and upload artifact
-
Submit and run Lava test job
-
Wait for publishable results from LAVA
In the first job, GStreamer is crossbuilt for the RPi using its build system, Cerbero, while running in a Docker container, for reproducibility. For this, we require a sysroot, a config file for Cerbero, and a Docker image. The sysroot was generated using Debos, a tool for creating Debian-based OS images. Through a simple YAML file, our sysroot contains all the minimal dependencies, tools, and setup required during build time. Next, the Cerbero config file lists the architecture and platform being targeted, path to the sysroot and its toolchain, output directories, and the option of including variants.
Variants are what Cerbero uses to configure and customize what gets included or excluded from the resulting build. A rpi variant was introduced to assist in modifying the build recipes of two particular GStreamer components: gst-plugins-base and gst-omx. As mentioned earlier, the RPi requires special configuration for GStreamer to be able to properly operate. The device itself contains a Broadcom System on Chip (SoC) and Broadcom firmware that applications must interface with in order to work with components like the GPU (VideoCore IV). This includes Broadcom implementations of APIs such as EGL and OpenGL ES. Both gst-plugins-base and gst-omx link against these libraries and so they have to be configured to use the Broadcom implementations if we are to have proper support.
Finally, Cerbero must be bootstrapped with necessary build tools and dependencies. To save some time, we install them in our Docker image along with our sysroot and config file. With that, GStreamer can be cross-built for the RPi where the resulting build artifact can be uploaded to a image artifact store. As this is a pipeline, the Jenkins job will finish by triggering another Jenkins job to cover the latter parts.
The second job submits a job to LAVA and waits until results are received after LAVA runs gst-validate. When writing a test for LAVA, we often provide two YAML files: One describes the setup of the job itself known as the job definition; the other describes the actual test that will be run on specified devices known as the test definition. The job definition contains information on how long the job should run, timeouts, the list of devices the job can run on, but most importantly, we are required to provide three actions: the deploy, boot, and test actions. If all you need is simple boot testing, the test action can be omitted. The deploy action allows us to specify the method of deployment for the images that the device will use and from which it will boot. The boot action specifies the boot method, boot commands, and login information, if applicable. The test action provides the locations of the repositories containing test definitions to be run. In addition, we can pass arguments as environment variables to our tests. Our job definition arranges deployment, over TFTP, images of the Raspberry Pi kernel, device tree blob, and a rootfs to boot using U-boot and NFS. It looks something like this:
actions:
- deploy:
timeout:
minutes: 60
to: tftp
kernel:
url: https://your.domain.com/zImage
type: zimage
modules:
url: https://your.domain.com/modules.tar.xz
compression: xz
dtb:
url: https://your.domain.com/bcm2709-rpi-2-b.dtb
nfsrootfs:
url: https://your.domain.com/rootfs.tar.gz
compression: gz
os: debian
- boot:
method: u-boot
commands: nfs
prompts: [ 'root@rpi2b:~#', '# ' ]
timeout:
minutes: 30
- test:
timeout:
minutes: 180
definitions:
- repository: https://your.git.host/lava-test-definitions
from: git
path: gst-validate/gst-validate.yaml
name: gst-validate
params:
CALLBACK_URL: {{callback_url}}
For Jenkins to submit the LAVA job definition, we use a tool developed at Collabora called LQA (LAVA QA). LQA simplifies the process of interacting with running or completed LAVA jobs, and can submit new jobs. A nice feature is that LQA supports Jinja2 templating when submitting jobs - this helps make our job definitions more flexible. We use this feature to include a callback URL that our job definition passes on into our test definition. The callback URL comes from the Webhook Step Jenkins plugin. This plugin basically creates a URL with a token that we can use to push data through a POST request along with a wait step that, you guessed it, waits to receive on that URL. The job will expect a xUnit file to be pushed as Jenkins has support for reading jUnit test results. Gst-validate is ran by calling gst-validate-launcher which has support for generating a xUnit report. With the report, we gain the benefit of having the results parsed and displayed in a visually readable format. Jenkins can also keep track of test failures between builds which helps us understand if there are any regressions. When translated into a Jenkinsfile, we simply write:
hook = registerWebhook()
// Submit
sh "lqa -c ${LQA_CONFIG} --log-file ${LOG} submit -v -t callback_url:${hook.getURL()} gst-validate.yaml"
// Wait
data = waitForWebhook hook
// Store Results
sh "mkdir -p results"
writeFile(file: "results/gst-validate-testsuites.xml", text: "${data}")
// Parse Results
junit "**/results/*.xml"
Moving on to the LAVA side, after submission, the images specified are deployed to our hooked-up RPi and booted to then run our test definition. The test definition starts by installing any dependencies necessary for our test to execute and then moves on to running a fetch-and-install script. This script fetches the latest build artifact from our image artifact store built in the first Jenkins job and installs it onto the device. In addition, it also fetches the packaged media assets used in the default validation testsuite as to avoid fetching them during the test. After fetching and installing dependencies, we verify the install and move on to running gst-validate. When the test run is complete, we check for our generated xUnit file and push it to the waiting Jenkins job. As stated earlier, the report can be parsed by Jenkins where we can neatly see the results from all tests and detect any regressions.
Presently, the GStreamer project is in the midst of a migration to Gitlab CI from Jenkins. In the meantime, the pipeline still requires much needed polishing and testing. There are a few areas for improvements in efficiency, speed, and correctness:
-
Improve fault tolerance at different stages of the pipeline. Specifically where if something were to go wrong during the LAVA test before gst-validate-launcher can complete then the Jenkins will end up waiting forever.
-
Improve GStreamer build times. The build job runs for an average of one hour and fifteen minutes.
-
Effort to get all tests to pass on the RPi. Currently, between fifteen to twenty percent of tests fail.
With more work, a robust pipeline can be ported to Gitlab CI, merged, and launch the process of adding more embedded devices.